Pascal Programming: § 1: Organization of Computers
We begin our discussion of computer organization with several basic definitions
and a distinction between
hardware and software (Section 1.1), then progress to a summary of various
types of software (Section 1.2). In Section 1.3, we discuss programming
procedure in terms of the preceding software and hardware organization
schemes.
1.1. Computer Hardware and Software.
As is customary in computer science, we begin by defining several
terms that we will be using frequently in subsequent discussion.
- Definition. A discrete set has elements that are distinct
from one another. A finite discrete set has a finite number of
elements.
Example. The Boolean set (or binary numbers) B = {0,1} is
a finite discrete set, since there are only two elements (zero and one).
Example. The set of counting numbers N = {0,1,2,...} is
a discrete set, but is not finite.
- Definition. A state map is a collection of values that
describe the state of a process or machine at a given time.
Example. A state map of human emotion could consist of
several values drawn from the list (happy, sad, peaceful,
etc.)
- Definition. A Boolean state map is a state map that has
Boolean values (i.e., consists of ones and zeroes).
- Definition. A digital computer is a finite, discrete
device that stores and manipulates a Boolean state map.
Remark. Digital computers are also called discrete processors
because they compute over discrete sets of numbers. Because the size of a
digital computer memory is finite, digital computers are sometimes called
finite discrete processors.
Digital computers are comprised of hardware (equipment)
and software (instructions that make the equipment operate).
Computer hardware consists of the following electronic or
electro-mechanical devices:
- Memory -- a collection of registers and storage
devices that store the computer's state map.
- Central Processing Unit (CPU) -- the "brains" of the
computer, which does the work of changing the state map
stored in memory.
- Input/Output (I/O) Processor -- manages and performs the
work associated with reading (or writing) information that
is added to (subtracted or copied from) portions of the
computer's state map.
- Peripherals -- include (a) devices that store ancillary
software and data, (b) output devices such as printers
and plotters, input devices such as the mouse or disk/tape
drive, as well as the keyboard or display device
(e.g., the monitor).
The following schematic illustration depicts a typical arrangement of
hardware in a personal computer or simple workstation.
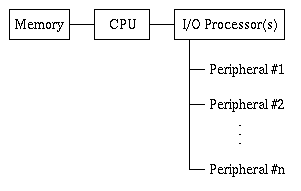
Figure 1.1.1. Organization of computer hardware in a von Neumann
architecture.
Such an arrangement is frequently called a von Neumann architecture
(VNA), so named for John von Neumann, who first reported this method of
connecting computer components. The VNA currently comprises over 95
percent of computer processors currently in use.
1.2. Software and Operating Systems.
Computer software includes sets of instructions (also called programs)
such as:
- Microcode -- low-level instructions that make the CPU run
correctly.
- Machine Code -- slightly higher-level than microcode, these
instructions are loaded directly into memory and comprise
a stored, executable program.
- I/O and Computational Libraries -- sets of procedures and
instructions that the I/O processor and CPU use to input or
output data, as well as compute various arithmetic, math,
and data handling operations.
- Application Software -- programs that users run to accomplish
various home, business, and scientific tasks such as word
processing (e.g., Word Perfect® or
Microsoft Word®),
spreadsheets (e.g., Quattro® or
Excel®), drawing or sketching
(e.g., AutoCAD® or Corel-Draw®),
and graphics (e.g., Adobe Photoshop®).
- Operating System -- interfaces application software with
libraries and (in very few cases) microcode in a convenient
manner that is transparent to (i.e., unseen by) the user.
- Ancillary Utilities -- in addition to the utilities provided
by the computer's operating system, there may be available
to the user compilers, linkers, and loaders for programming
languages such as Pascal, FORTRAN, C, and C++.
The following illustration schematically depicts the arrangement of
software in a program development sequence, as discussed in Section 1.3.
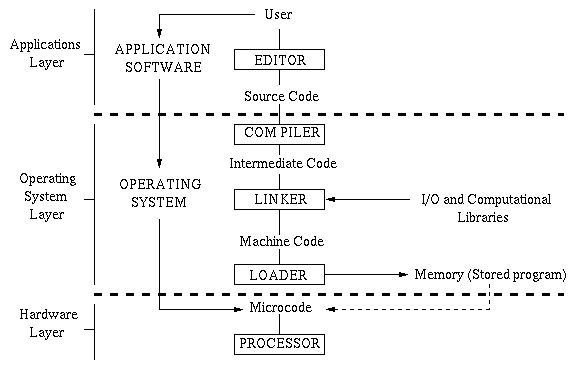
Figure 1.2.1. Organization of computer software for compilation
and applications software execution. Light solid lines denote flow
of data, while light dotted lines denote flow of control.
Of particular interest is the operating system, which performs a
variety of functions that include:
- Timekeeping -- interrogates the system clock (hardware)
to determine time-of-day and date, as well as the duration
of each sequence of instructions executed.
- Input/Output -- whereby instructions or data are moved to or
from memory or secondary storage (e.g., a disk drive).
- User Interface and I/O Management -- which includes managing
the layout and display parameters (e.g., color and resolution)
of windows in which application software is run, inputting
instructions from pointing devices such as the mouse, and
managing user input from the keyboard.
- Compilation Management -- including tasks that constitute
portions of the software development process, such as (a)
editing programs developed by system users, (b) program
translation into low-level machine code, and (c)
linking user programs with
various libraries to achieve versatility. This process
is shown schematically in Figure 1.2.1.
- File and Directory Management -- organizing information
stored in disk and tape drives in an orderly, hierarchical
fashion.
Note that the operating system serves as a link
between the low-level functions of the hardware and the higher
level processes that occur in application software. This linking
process must be accomplished in a manner that is transparent to (i.e.,
unseen by) the user, so that the user will not waste time or cause problems
by becoming involved
in low-level implementational details of program compilation and
execution. Additionally, the operating system must perform these
functions in a convenient manner, to avoid distracting the user from
performing tasks that the application software is designed to perform
or assist.
In the past (i.e., early days of computing), operating systems were
more cumbersome and provided fewer utilities. This was due in part to
the small amount of memory available (resulting from relatively primitive
technology), as well as the simpler types of software in use at that time.
Modern operating systems support graphical user interfaces, multi-window
systems, and multiprocessing (running several different programs at the
same time). Furthermore, software development tools have increased in
sophistication to include user-friendly compilation and linking, as
discussed in the following section.
1.3. Overview of Computer Program Creation and Implementation.
The software development process consists of numerous steps, which
we shall overview shortly. Program editing, compilation, and
linking are a part of this process, and are supported by the following
types of software:
- Text Editor -- can be thought of as a word processor
for programmers, and facilitates the creation and modification
of text files that contain high-level instructions. These files
are customarily called source code.
- Compiler -- accepts source code, which is automatically
translated into intermediate code (IC). Often, the
IC is comprised of a mixture of binary code (ones and zeroes)
interspersed with recognizable words or symbols from source
code.
- Linker -- after the program is compiled, it is linked to
I/O and computational libraries, and then to the runtime
libraries. This transforms the intermediate code into
machine code (MC) that can be loaded directly
into memory and calls microcode routines that operate the
CPU.
- Loader -- copies the machine code to memory and sets
up address pointers so that the MC can control
the microcode, which controls the processor.
- Debugger -- a utility that is often furnished with a
compiler or operating system, which enables one to check
on the execution of a program while it is running. The
purpose of a debugger is to help the software developer
locate erroneous expressions within the source code.
A debugger often accepts machine code, and generates a
list of errors based on breakpoints or
tracepoints (places in the source code where an
audit of computed or input values is called for), as
well as a watchlist (names of variables whose
value is reported as soon as it is changed).
Some debuggers are applied to the intermediate code
produced by the compiler, but sometimes contains an
interpreter that is applied to source code.
Given the preceding software, we next discuss the process of creating
and running a program from the software development perspective. In
practice, the software development cycle involves the following
steps:
- Requirements -- The software design team gathers facts
about the software to be created. Sources of information
are management, marketing, software engineers, and the
customer (who may be the end user of the software). For
example, one could consider the following issues:
- Functionality -- What tasks is the software
supposed to perform, and in what manner (from
the perspective of the hardware or the user)?
- Portability -- What processors or workstations
is the software supposed to support? For example,
IBM-PC, Apple Macintosh®, or a UNIX
workstation.
- Interfacing -- Does the customer or user require
a graphical user interface or special software
that allows the user, system hardware, or peripherals
to input (output) data to (from) the software?
- Access -- What special types of data are to
be used by the software, and are they stored in
a place that requires, for example, special access
permission?
- Security -- If data must be stored or handled
in a special way that requires protection (e.g.,
codes or ciphers called encryption), who
will handle the data, and what level of security
is required? How will passwords be apportioned
or shared?
- Timeliness -- How soon does the customer or
client expect the software to be delivered?
What are the critical dates?
- Cost -- How much effort (person-years) and
what type of effort (e.g., engineers, programmers)
will be required to design, code, and test the
software? What equipment will be involved?
Requirements are often expressed first at a high
level (generalities) and then elaborated to a low
level (specific details). This allows the
software designer to formulate basic ideas about
parameters that describe or limit various
requirements categories. Such effort leads
naturally to the production of a
software specification, which is discussed as follows.
- Specification -- Given parameters or limits on various
categories of requirements, the software development team
formally organizes such parameters in terms of a set of
alphanumerical values called a specification.
For example, software
reliability could be expressed as Mean Time Between
Failure (MTBF) ranging from 15,000 hours to 18,000 hours
of operation. Similar to requirements, specifications are
expressed at high and low levels, in order to first roughly
estimate the value ranges, then to refine them to be more
consistent with the customer's needs and established practice.
- Design -- A key component of the software development
process is the expression of system structure and function
in modular form. Software designs can be expressed
in various representations that convey similar
information. For example, Figure 1.3.1 schematically
illustrates a program that is comprised of a Main Task,
which has two Subtasks. The first subtask has two operations
that might be executed sequentially. Software designs can
be expressed hierarchically or in nested fashion, in
terms of control or data flow, or in network form, to name
but a few formats.
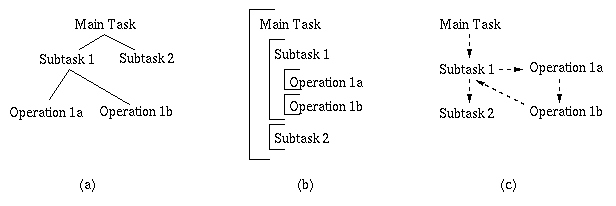
Figure 1.3.1. Representation of a small software module that has
a Main Task comprised of two Subordinate Tasks, where the first Subtask
has two operations. (a) Hierarchical representation, where solid lines
indicate the "part-of" relationship; (b) Nested structural relationship,
where flow of control proceeds from the top of the Figure downward; and
(c) Network representation, where dotted lines denote flow of control.
Note the differences in Figure 1.3.1 -- a) describes a type of
membership, b) describes control flow, and c) denotes
dependencies as well as control flow. In the field of
software engineering, there are extensively many such
representations, few of which can be straightforwardly and completely
translated to each other. Thus, the preceding representations are
presented as conceptual aids to design only, and should not be thought
of as substitutes for programming, which they are not.
Definition. An exception is an abnormal condition
that occurs during program execution, which a given software
system must either ignore or deal with. The latter activity
is called exception handling.
Example. Using the wrong mouse button in a given context
may cause an exception to occur.
Definition. An error is an exception that may cause
interruption of program execution, or the production of inaccurate
results.
Example. A "bug" in the coding process
can often cause runtime errors in the coded software,
such as writing to the wrong file, or loss of data.
Definition. A fault is a serious exception that may
cause execution of a given software system to terminate.
Example. A mistake in the memory fabrication process may
cause a chip to have a defect that changes one or more bits of
a stored program, thus causing the program to "hang up" or "crash".
In computer science terminology, the latter behavior is called
"halting".
The software design process also emphasizes handling of expected
difficulties, exceptions, errors, and faults that are typically
encountered during program execution. For example, if a user presses
the wrong key, then the software should sense this error and cause
a procedure in the software system to deal with the error. Typically,
the computer will emit a beeping sound, and may display a message
that (a) tells the user he pressed the wrong key and (b) displays
the correct keys to press in the given context.
- Coding -- After the high-level design is well along,
programmers can begin coding the software system's high-level
structure. In large programs or systems, some standard low-level
functions (e.g., text or image display) may also be coded in terms
of libraries (collections of small programs). When the
low-level design is approved by the customer or client, coding begins
in earnest. In modern software engineering practice, approval
can occur in stepwise fashion, allowing coding to proceed
concurrently with design of other modules.
- Debugging -- During (or after) compilation of the prototype
software system, errors are detected that prevent the software from
compiling (functioning) reliably or correctly. These errors must
be identified and corrected, which is often accomplished using
a software tool called a debugger. Two types of debugging
are generally employed:
- Source level debugging can detect and identify coding
errors such as misspelled names or erroneously formatted
calls to routines stored in libraries.
- Runtime level debugging helps the programmer track
values associated with given variables and outputs of
modules, functions, or operations. This procedure is
generally used to detect flaws in program logic or
erroneous sequences of computational operations that
cause a program to yield inaccurate results.
- Testing -- Following the debugging process, software is run
using various input datasets to collect data that can describe:
- Reliability -- How often did the software system
crash or caused exceptions or faults to occur? Did
such failure rates meet specifications? If not, why
not? Additionally, what modules or statements were
associated with these undesirable events?
- Performance -- Did the software produce the
expected results with specified computational and
storage efficiency? If not, why not, and which
modules or operations were primarily responsible
for the slowdown?
- Accuracy -- Were the numerical results accurate to
within specified error? Do further compromises or
tradeoffs in the design need to be made to render the
results more accurate?
Inherent in the software testing process is analysis of test results,
which yields important information about local performance and
accuracy deficits. Such analyses highlight specific parts of the
software that need to be redesigned, recoded, and retested until
performance meets the design specification. In some cases, it may
be possible (and is often desirable) to improve upon the
design specification. The required analysis is often complicated
due to interactions between software components, but can be
greatly simplified by thorough observance of the principles of
modular software design.
- Documentation -- In order for users and other programmers
or software designers to understand, operate, and maintain
a given software system, software designers and programmers
of that system should provide adequate documentation. This
usually takes the following forms:
- Development Reports -- summarize key requirements,
specification, and design decisions for future reference.
Additional material concerns test and analytical results,
design changes and recoding, etc. These documents are usually
proprietary to the organization that developed the software
system, and are hence not released to the customer or client
except in specific problem-solving situations.
- User Manual -- contains an overview of the software
system's structure and function, then presents detailed
descriptions (with examples) of system operation.
- Technical Reference Manual -- primarily intended
for programmers and software engineers, this document details
software system structure and function, often down to the
level of individual statements or sub-expressions. Sufficient
detail should be provided to permit software redesign to
occur with relative ease and efficiency. It is often
useful to include requirements and specifications in this
document, for future reference during system modification.
- Tutorials and Help System -- may be provided in
documentary or on-line form, or both. Tutorials are
story-like programs or documents that "walk" the novice
user through various program operations and tasks. A
tutorial is usually written with linear narrative flow,
and difficult operations are often expressed stepwise.
The Help System is usually on-line and
available for answering questions about specific operations.
In contrast to the tutorials, the help system is best
accessed in a random manner, similar to the difference
between reading a novel and looking up a topic in an index.
Thus, a wide variety of software and documentation is produced during the
development cycle. Some of this material remains with the generating
organization, while the remainder may be distributed to customers.
A part of the software development process that we have not discussed
in detail concerns redesign and recoding of modules that
(a) are poorly designed in the first place, or (b) must be redesigned to
conform to modifications requested by the customer after the specification
and design have been completed. This latter problem is key to the
high failure rate of early prototype software. For example, rather than
signing off
on a specification and letting the software engineering process proceed
in an orderly manner, additional customer requests can create design and coding
nightmares that may persist through the life of a software system (i.e.,
through many future revisions of the software). Such rework is costly
in terms of time, money, and effort, since the software development
process must be repeated in the presence, and under the constraint, of
preexisting requirements and specifications. Fitting such modifications
into an existing design is often difficult and can easily compromise the
integrity, reliability, and ease of maintenance of a given software system.
If there is a moral to this story of the software development process, it
is "Do it right the first time". This implies careful requirements
gathering and specification, careful coding, and painstaking test and
analysis of results. Thorough, detailed, easily read documentation is
also necessary. As an additional consideration, today's global marketplace
often requires that multiple sets of documentation be maintained
consistently across various hardware and software platforms, as
well as in various dialects of natural language (e.g., English, Japanese,
German, French, etc.) The requirements and vagaries of language translation
often conspire to make this a difficult goal. Research has only begun to
successfully address the practical implementation of automated document
translation, which remains an open area of endeavor.
This concludes our overview of computer organization.
We next overview the DOS operating system and DOS commands.
References