Assumption. Let P1,P2,P3 :
F -> F and let
n1 = |range(P1)|
with n2 = |range(P2)|. If P3
is obtained from some function of the output of P1 and
P2, then domain(P3)
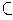 range(P1)
× range(P2). However, we previously assumed
that range(Pi) = domain(Pi) for
i = 1..3. The preceding expression can thus be rewritten as:
range(P1)
× range(P2). However, we previously assumed
that range(Pi) = domain(Pi) for
i = 1..3. The preceding expression can thus be rewritten as:
range(P3)
range(P1)
× range(P2),
|range(P3)| < |range(P1)| · |range(P2)| .
In the limiting case, where the preceding relation is the equality relation, we have n3 = n1 · n2.Observation. The amount of information output by a continually productive source is a strictly increasing function of time.
Definition. Let H denote the information content (or entropy) of a process, and let H denote the operation that computes H. In the first Observation of this section, if Hi = H(Pi) for i = 1..3, then the entropy of P3 is given by H3 = H1 + H2.
Lemma 1. Given the preceding assumption and processes P1,P1 : F -> F, the entropy H(P3) of a process P3 = f(P1,P2) is given by
H(P3) = log(n3) = log(N(P3))
if the following conditions are satisfied:
- P1 and P2 have equiprobable outcomes n1 = N(P1) and n2 = N(P2).
- P3 has n3 = n1 · n2 equiprobable outcomes.
- If Hi = H(Pi) for i = 1..3, then H3 = H1 + H2.
- Proof. Assume that conditions 1-3 hold.
Note that H = log is the only function that
satisfies conditions 1-3 simultaneously, since
n3 = n1 · n2,
H(P3) = log(n3) =
log(N(P3)), and
log(n3) = log(n1·n2) = log(n1) + log(n2) .
Thus, if H = log, then H3 = H1 + H2, and the lemma holds.
Example. Let n1 = N(P1) = 32 and n2 = N(P2) = 64. It follows that H1 = 5 and H2 = 6. If n3 = n1 · n2, then H3 = H(P3) = H1 + H2 = 11 bits. As a result, P3 has 211 = 2048 possible outcomes.
We next explore the case when two processes have outcomes that are not equiprobable.
pi = ni/n , where i = 1,2 .
Recall that the entropy associated with one message among n equally likely outcomes is denoted by H(n) = log(n). However, for n1/n of the time, H(n1) = log(n1). Symmetrically, H(n2) = log(n2). Thus, the net entropy is given byH = log(n) - (n1/n)·log(n1) - (n2/n)·log(n2) ,
which can be expressed in terms of probabilities as:H = -(p1/n)·log(p1) - (p2/n)·log(p2) .
Since p1,p2 < 0, the logarithms are negative and H > 0.Via the preceding equation, we can express information content in terms of a discrete probability distribution over a random variable. The following theorem is illustrative.
Theorem 2. Let a process P have n possible outcomes that exhibit individual probabilities pi, where i = 1..n. The entropy of P, denoted by H(P), is given by
H(P) = 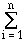 -pi · logpi .
-pi · logpi .
 (I)
(I)
- Proof. The proof, which is well known, follows
from the preceding remark and
induction on i.
We next restate the law of additive combination of information, with proof given in [Ham86] and [McE77].
H(P) = H(P1) + H(P2) .
Theorem 4. If a process P is comprised of two processes P1 and P2 that are not statistically independent, then the entropy of P is given byH(P) < H(P1) + H(P2) .
The following theorem of maximum information is stated without proof, which may be assigned as an exercise or as homework.Theorem 5. If a discrete process P has n outcomes that exhibit individual probabilities pi, i = 1..n, then P yields maximum information when pi = 1/n.
Definition. If an alphabet has n symbols, then the average rate is given by log(n)/n bits per symbol.
Example. The modern English alphabet F has 26 symbols plus the ten digits 0-9. Excluding the digits, H(F) = log(26) = 4.5 bits/symbol. If the probability of each letter is taken into account and we apply Equation (I), then H(F) < 4 bits/symbol. Using a text corpus abstracted from technical documents, Shannon showed that the actual information content of English is approximately one bit per symbol, since the nonuniform distribution of n-grams implies statistical dependence among symbols. In practice, various entropy values can be obtained using different text corpi expressed in other languages.
We next discuss the computation of measures of information content in encrypted text.
Example. Assume that the substitution cipher T : FX × K -> FX, where K is called the keyspace and T is one-to-one and onto. Let |F| = 26, as before, and let K = F. Recall from previous examples that there are 26! (i.e., |F|!) possible keys of length 26 symbols.
Let us construct a 26-character key that encrypts a 40-character
text (i.e., |X| = 40). The information content of the
key is given by Hk = log(|F|!)
= log(26!). If the plaintext has entropy
Ht,
then the substitution has entropy H(T) <
Ht + Hk, since the plaintext and key may
not be statistically independent.
From Theorem 5, a 40-character text has maximum entropy
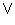 (H(T))
(H(T))
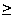 Ht + Hk = Ht +
log(26!) .
Ht + Hk = Ht +
log(26!) .
Ht 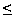 (Ht)
- Hk = 40 · log(26) - log(26)!
= 100 bits .
(Ht)
- Hk = 40 · log(26) - log(26)!
= 100 bits .